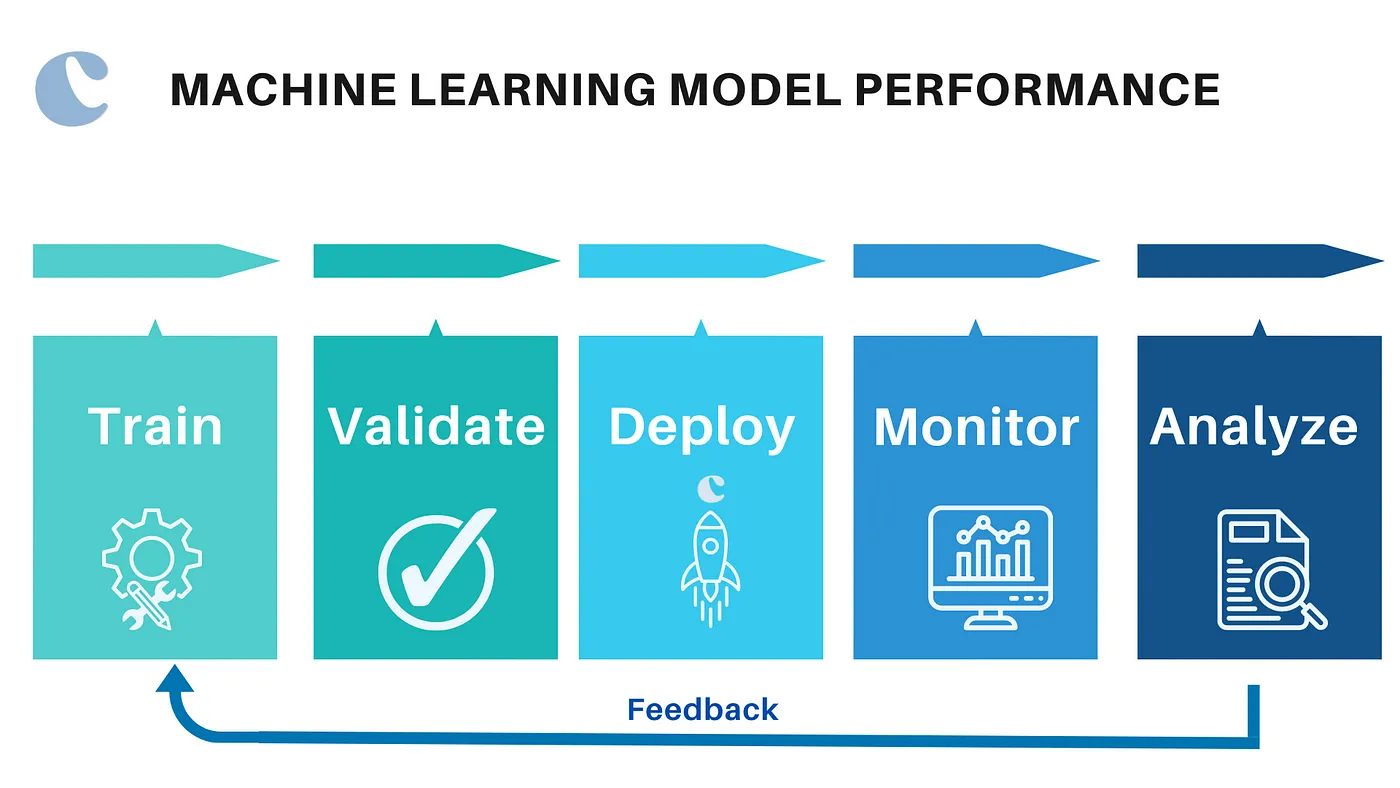
Understanding the Importance of Model Performance in Machine Learning
In the rapidly evolving world of machine learning (ML), the performance of models dictates their effectiveness in practical applications. Whether predicting customer behaviour, diagnosing medical conditions, or automating complex tasks, the accuracy and reliability of ML models play a pivotal role in determining their success. As organizations increasingly rely on data-driven decisions powered by machine learning, optimizing model performance has become crucial.
The performance of an ML model is not just about achieving high accuracy; it involves a nuanced balance of various metrics and considerations that reflect the model's ability to generalize from training data to real-world scenarios. This balance ensures that models perform well not only on paper but in actual deployment, where they impact real decisions and real lives.
The Impact of Data on Machine Learning
The adage 'garbage in, garbage out' is particularly apt in the context of machine learning. The quality and quantity of data used to train ML models are fundamental to their success. Good data fuels the model's ability to learn effectively and make accurate predictions, while poor data can lead to misleading results and failed projects.
Data Quality
High-quality data is accurate, complete, and representative of the scenarios the model will encounter in production. Here's why quality is crucial:
- Accuracy: Data with errors or inaccuracies can mislead the training process, causing the model to learn incorrect patterns and apply them inappropriately.
- Completeness: Missing values can significantly impact the performance of many ML algorithms, as they rely on a full dataset to discern patterns accurately.
- Representativeness: Data must reflect the real-world diversity and range of scenarios that the model will face. Data that is not representative can cause the model to perform well in a test environment but fail in real-world applications.
Data Quantity
While the quality of data is paramount, the quantity also plays a critical role. The complexity and depth of learning possible with an ML model are often directly related to the amount of data available.
- Volume: More data provides more examples from which the model can learn, improving its ability to generalize and reducing the likelihood of overfitting.
- Variability: Large datasets that include a wide range of input variations give the model a broader perspective and a better ability to handle unexpected inputs in real-world operations.
Best Practices for Ensuring Data Quality and Quantity
- Data Collection: Develop robust mechanisms for data collection that ensure data integrity and minimize the introduction of biases.
- Data Cleaning: Implement thorough cleaning processes to remove inaccuracies and handle missing values appropriately.
- Data Enrichment: Consider augmenting your dataset with additional sources to enhance its diversity and representativeness. This could involve using synthetic data or integrating datasets from different but related domains.
- Continuous Data Updates: Regularly update the training dataset with new data collected from operational environments to keep the model relevant as conditions change.
Data forms the foundation of every machine learning model. Ensuring high-quality and sufficient data is the first and most crucial step in building effective and reliable ML models. With the right data, you set the stage for your model to learn effectively and perform predictably in real-world applications.
Feature Selection and Engineering
The features used to train machine learning models greatly influence their ability to learn and make accurate predictions. Feature selection and engineering are critical processes that involve identifying the most relevant variables and constructing new features to improve model performance.
Feature Selection
Feature selection is about identifying the most impactful features from the dataset. This step is crucial because irrelevant or redundant features can confuse the model, leading to poor performance.
- Relevance: Features directly influencing the output are considered relevant. Identifying and focusing on these features can significantly enhance model accuracy.
- Redundancy: Removing duplicate or highly correlated features simplifies the model without sacrificing performance, improving both training speed and interpretability.
Feature Engineering
Feature engineering is the process of using domain knowledge to create new features from the existing data, which can help to increase the predictive power of the machine learning model.
- Transformation: Applying transformations like logarithmic, square root, or binning can help in normalizing or structuring the data more effectively for the model.
- Interaction: Creating interaction features that capture the combined effects of two or more features can unveil complex patterns in the model that are not apparent from the individual features alone.
- Aggregation: For data that spans across time or groups, aggregation (such as mean, sum, or max) can help to capture the essence of the data over the specified period or group.
Best Practices for Feature Selection and Engineering
- Iterative Process: Feature engineering and selection should be iterative. As the model evolves and more insights are gained, revisiting feature selection and engineering can yield further improvements.
- Use Automated Tools: Leverage tools like feature importance provided by machine learning frameworks, or automated feature selection tools to help identify the most effective features.
- Cross-Validation: Use cross-validation to evaluate the impact of newly created features on the model's performance to ensure they are genuinely beneficial.
Effective feature selection and engineering are pivotal in enhancing a machine learning model's accuracy and efficiency. By carefully choosing which features to include and finding innovative ways to transform and combine existing information, data scientists can significantly boost model performance. This process not only helps in making the model more robust but also more adaptable to complex real-world scenarios.
Model Complexity
Model complexity refers to the intricacy of the mathematical model used in machine learning algorithms, encompassing the number of parameters, the depth of learning, and the sophistication of the model structure. A well-calibrated complexity level is essential for maximizing performance without succumbing to common pitfalls like overfitting or underfitting.
Overfitting vs. Underfitting
- Overfitting: Occurs when a model learns the training data too well, including the noise and outliers, which leads it to perform poorly on new, unseen data. Overfitting is often a result of excessive model complexity.
- Underfitting: This happens when a model is too simple to learn the underlying pattern of the data, resulting in poor performance both on training and new data. This often occurs with insufficient model complexity.
Choosing the Right Model Complexity
The key to effective machine learning is finding the right balance in model complexity:
- Data Size and Complexity: More complex models generally require larger amounts of data to train effectively. With insufficient data, simpler models are preferable to avoid overfitting.
- Computational Resources: More complex models demand more computational power and longer training times. The available resources might limit the feasible complexity of the model.
Techniques to Manage Model Complexity
- Regularization: Techniques like L1 and L2 regularization are used to penalize overly complex models, effectively reducing the risk of overfitting.
- Pruning: In neural networks, pruning can be used to remove unnecessary nodes, reducing the model's complexity without significantly affecting its performance.
- Cross-Validation: Helps in determining the optimal complexity of the model by evaluating its performance on different subsets of the data.
Best Practices for Managing Model Complexity
- Start Simple: Begin with simpler models to establish a performance baseline. Gradually increase complexity as needed based on performance metrics.
- Use Validation Data: Always keep a separate validation dataset to test the model's performance as its complexity increases. This helps in monitoring for signs of overfitting.
- Iterative Refinement: Continuously refine the model by adjusting its complexity based on ongoing results from new data and additional testing.
Balancing model complexity is crucial in machine learning. Too simple, and the model may fail to capture important nuances; too complex, and it may become ungeneralizable and inefficient. By carefully managing model complexity through techniques like regularization and cross-validation, data scientists can build models that not only perform well on training data but also generalize effectively to new, unseen datasets.
Algorithm Selection
Algorithm selection is pivotal in the machine learning pipeline. The choice of algorithm can significantly impact the model's performance, training time, and ability to generalize to new data. Selecting the right algorithm involves understanding the strengths and weaknesses of each and matching them to the specific needs of the dataset and problem at hand.
- Problem Type: Different algorithms excel at different types of problems. For instance, decision trees and their ensembles like Random Forests are great for classification and regression tasks, whereas support vector machines might be better for complex classification tasks in high-dimensional spaces.
- Data Characteristics: The size, quality, and nature of the data can dictate the suitability of an algorithm. Algorithms also vary in their sensitivity to skewed data and outliers, which can influence the decision.
- Accuracy, Training Time, and Scalability: These are crucial factors to consider. Some algorithms may offer higher accuracy but require longer training times or more computational resources, making them less scalable for large datasets.
Popular Machine Learning Algorithms
- Linear Regression/Logistic Regression: Simple and fast, these algorithms are well-suited for linearly separable data.
- Decision Trees: Provide intuitive models that are easy to interpret but can be prone to overfitting.
- andom Forests and Gradient Boosting Machines (GBM): Offer more robust and accurate models at the cost of increased complexity and longer training times.
- Neural Networks/Deep Learning: Highly flexible and powerful, especially for tasks involving images, text, or where complex data patterns need to be captured.
Experimentation and Evaluation
Choosing the most effective algorithm typically requires experimentation. Data scientists often compare several algorithms on the same dataset to determine which performs best under given constraints.
- Cross-Validation: Use cross-validation techniques to robustly assess the performance of different algorithms.
- Performance Metrics: Evaluate algorithms based on relevant performance metrics that align with business objectives, such as accuracy, precision, recall, F1 score, and area under the ROC curve (AUC-ROC).
- Iterative Testing: Continuously test and tune different algorithms with various hyperparameters to find the optimal setup for your specific challenge.
Best Practices for Algorithm Selection
Effective algorithm selection is fundamental to developing successful machine learning models. By carefully considering the type of problem, data characteristics, and required performance, and by rigorously testing different algorithms, data scientists can tailor their approach to meet specific needs and optimize outcomes.
- Baseline Models: Start with simple baseline models to establish initial performance benchmarks.
- Up-to-date Algorithms: Stay current with the latest developments in machine learning, as newer algorithms or variations might offer improvements over traditional approaches.
- Comprehensive Documentation: Document the testing and evaluation process for each algorithm, including configurations and results, to build a knowledge base for current and future projects.
Subscribe to Our Newsletter
Stay updated with our latest insights.