Solution Team
Jul 11, 2024
Category: ML Model

An Artificial Intelligence (AI) model is a mathematical framework or algorithmic architecture that enables machines to make decisions based on data. They are created through machine learning (ML), where models are trained and tested using large datasets to ensure they can perform tasks such as classification, prediction, and pattern recognition.
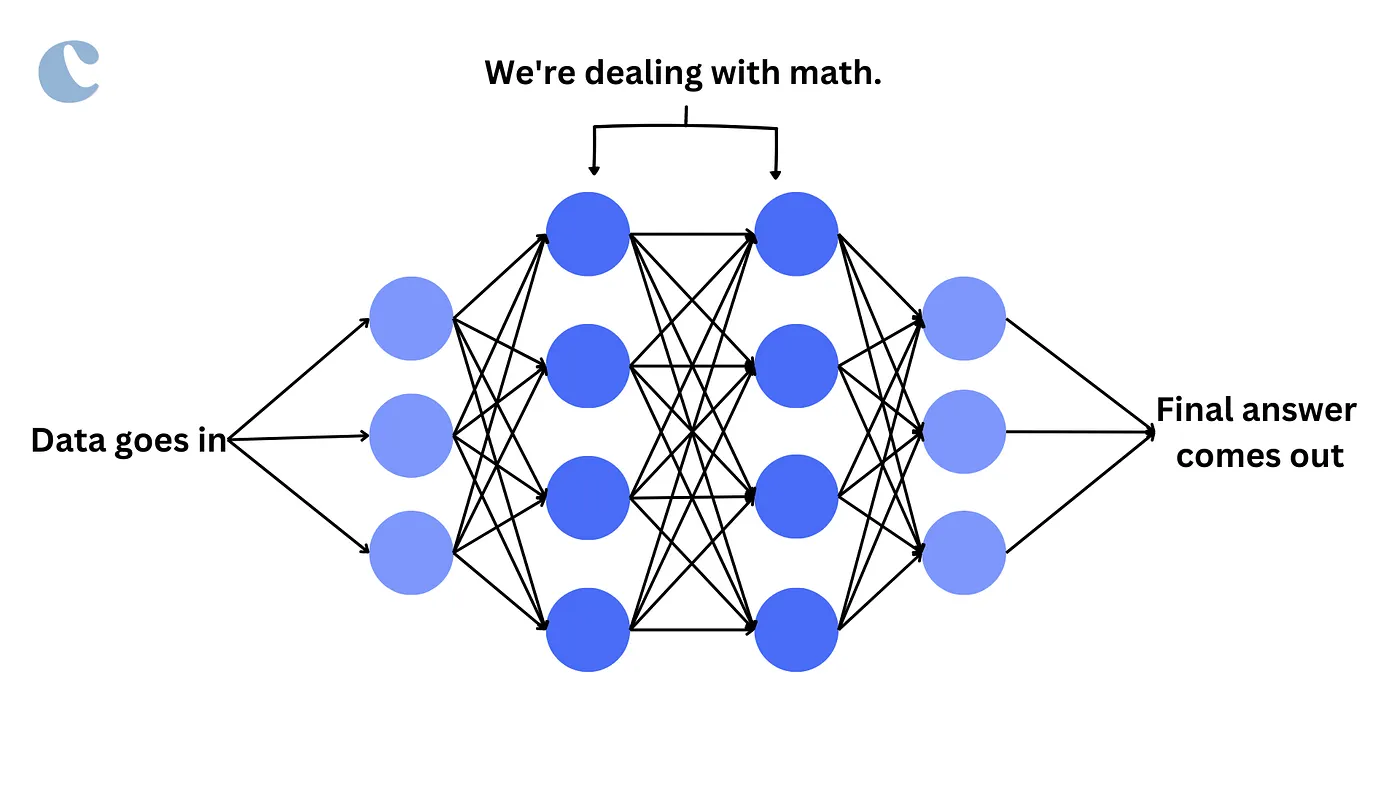
AI models are crucial in modern technology solutions, driving innovations in sectors like healthcare (predicting patient outcomes) and automotive (enabling self-driving cars). The ability of AI models to learn from data and improve over time makes them invaluable for any data-driven organization.
AI model architecture refers to the structured arrangement of algorithms and computational layers that work together to process data and produce outcomes. Different architectures are designed to handle specific tasks and data types effectively.
Neural networks, modeled after the human brain, consist of interconnected nodes (neurons) arranged in layers that transmit signals from input data through the network to produce an output.
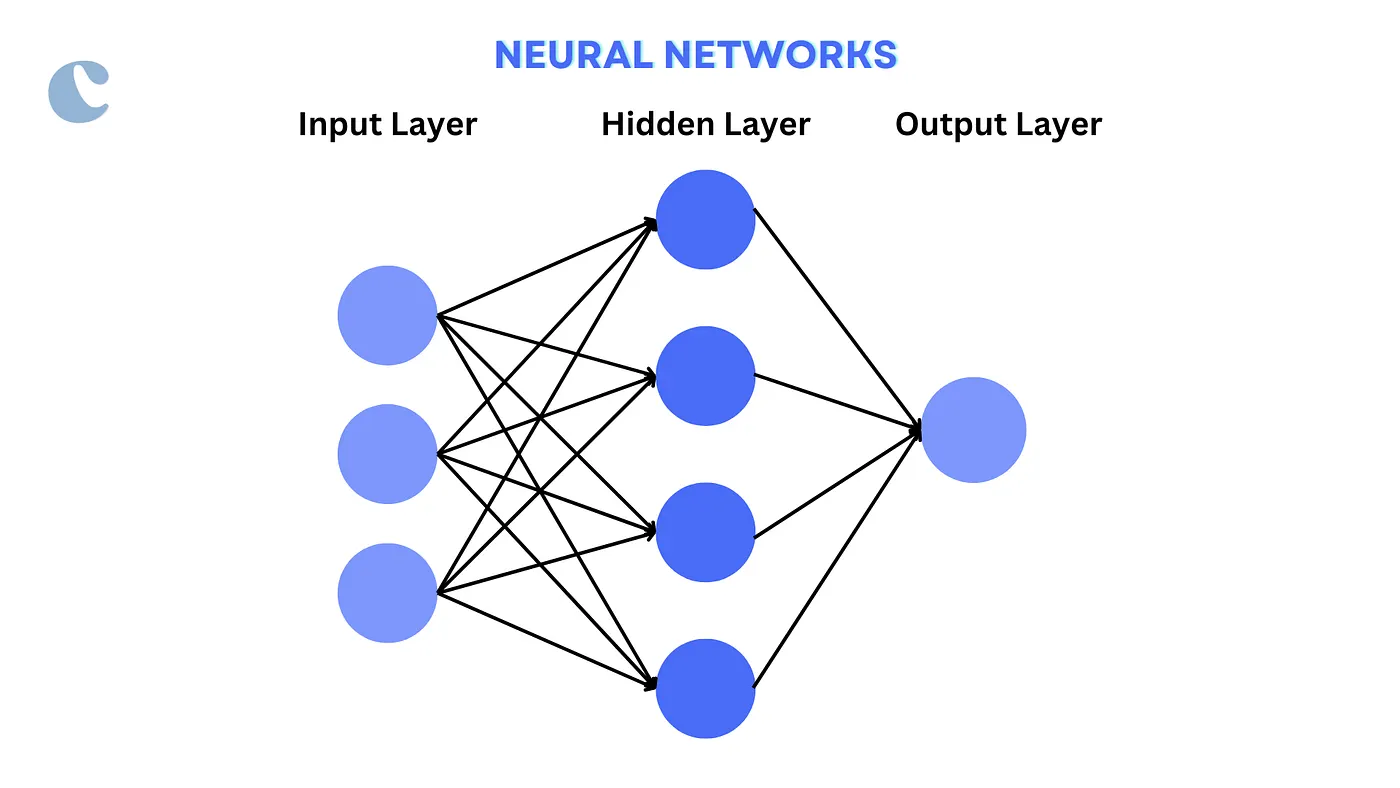
Pseudocode for a simple neural network:
def neural_network(input_data, weights):
hidden_layer = relu(np.dot(input_data, weights[0]))
output_layer = sigmoid(np.dot(hidden_layer, weights[1]))
return output_layer
def relu(x):
return np.maximum(0, x)
def sigmoid(x):
return 1 / (1 + np.exp(-x))"
Decision trees are flowchart-like structures where each internal node represents a “test” on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label (decision).

Pseudocode for training a decision tree:
def decision_tree(data, labels):
if all_same_class(labels):
return Leaf(class=labels[0])
else:
best_feature, threshold = find_best_split(data, labels)
left_data, right_data, left_labels, right_labels = split_data(data, labels, best_feature, threshold)
left_tree = decision_tree(left_data, left_labels)
right_tree = decision_tree(right_data, right_labels)
return Node(feature=best_feature, threshold=threshold, left=left_tree, right=right_tree)Support Vector Machines are supervised learning methods used for classification and regression by finding the hyperplane that best divides a dataset into classes.
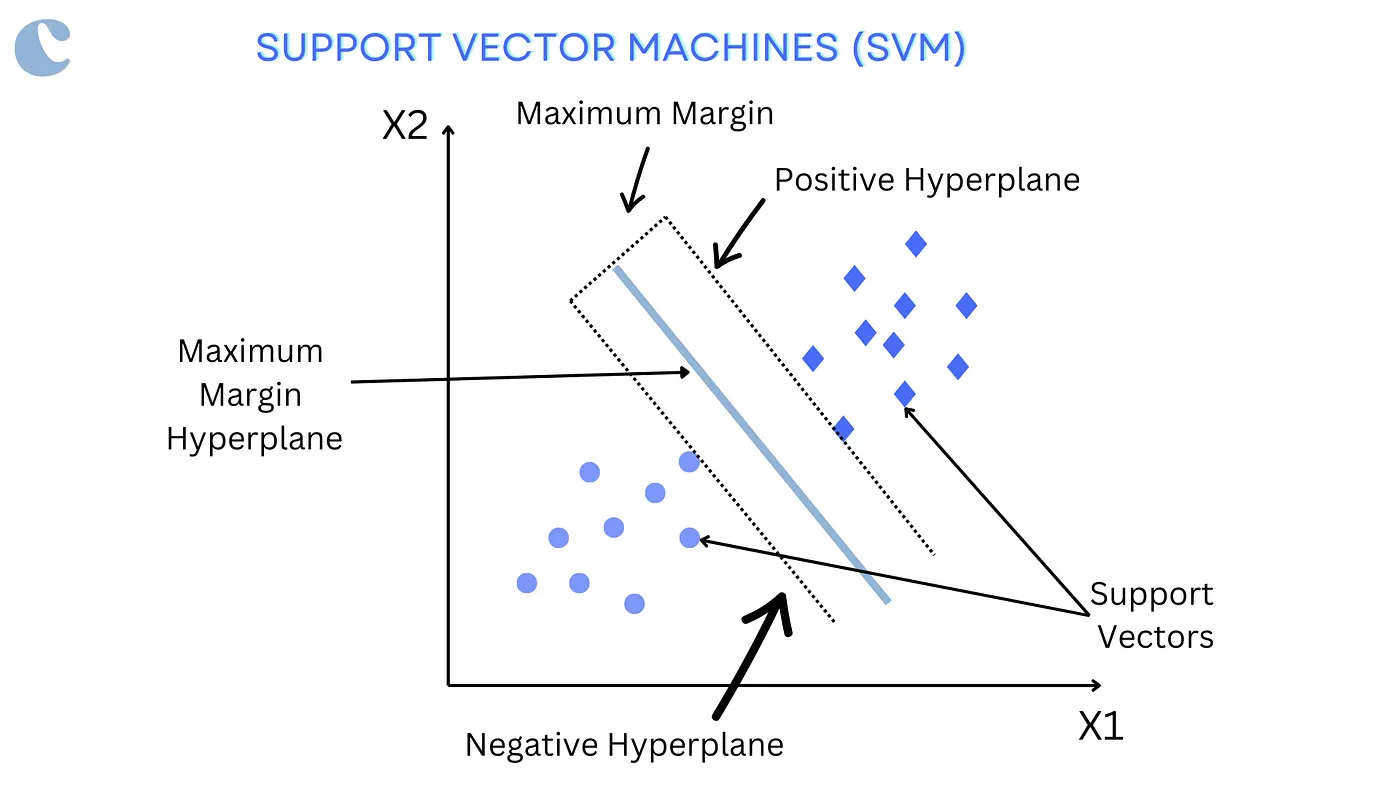
Pseudocode for SVM Algorithm:
def svm_train(data, labels, C, epochs, lr):
w, b = initialize_parameters()
for epoch in range(epochs):
for i in range(len(data)):
if labels[i] * (np.dot(data[i], w) + b) < 1:
w -= lr * (2 * w / C - np.dot(data[i], labels[i]))
b += lr * labels[i]
else:
w -= lr * (2 * w / C)
return w, bUnderstanding the architecture of AI models is crucial as it directly influences their capability to process and analyze data effectively. Each type of architecture has its strengths and is suited to specific kinds of data and tasks, impacting the model's performance, interpretability, and ease of integration into existing systems.
Effective data handling and preprocessing are fundamental to optimizing the performance of AI models. Preparing raw data enhances the model's ability to learn efficiently and accurately.
Pseudocode for data cleaning:
def clean_data(data):
data.drop_duplicates(inplace=True)
for column in data.columns:
if data[column].isnull().any():
data[column].fillna(data[column].median(), inplace=True)
return dataPseudocode for data normalization:
def normalize_data(data):
for column in data.columns:
data[column] = (data[column] - data[column].mean()) / data[column].std()
return dataPseudocode for feature selection (using variance threshold):
def select_features(data, threshold):
selected_features = []
for column in data.columns:
if data[column].var() >= threshold:
selected_features.append(column)
return data[selected_features]Proper data handling and preprocessing streamline the training process and significantly impact the effectiveness and efficiency of the resulting AI model. Ensuring the data is clean, well-prepared, and thoughtfully engineered helps data scientists build more accurate and reliable models.
Training algorithms are central to developing AI models, dictating how a model learns from data to make accurate predictions or decisions.
Supervised learning involves training a model on a labeled dataset, where the desired output is known.
Pseudocode for feature selection (using variance threshold):
def linear_regression(X, y, lr, epochs):
weights = np.zeros(X.shape[1])
for epoch in range(epochs):
predictions = np.dot(X, weights)
errors = predictions - y
weight_gradient = np.dot(X.T, errors) / len(y)
weights -= lr * weight_gradient
return weightsUnsupervised learning algorithms identify patterns or groupings in data without prior labeling.
Pseudocode for k-means clustering:
def k_means(data, k, epochs):
centroids = initialize_centroids(data, k)
for epoch in range(epochs):
clusters = {i: [] for i in range(k)}
for point in data:
distances = [np.linalg.norm(point - centroid) for centroid in centroids]
cluster_index = distances.index(min(distances))
clusters[cluster_index].append(point)
centroids = [np.mean(clusters[i], axis=0) for i in range(k)]
return centroidsReinforcement Learning (RL) involves training models to make a sequence of decisions by rewarding desired behaviours and penalizing undesirable ones.
Pseudocode for a basic reinforcement learning model:
def reinforcement_learning(environment, episodes):
for episode in range(episodes):
state = environment.reset()
done = False
while not done:
action = model.choose_action(state)
next_state, reward, done = environment.step(action)
model.update(state, action, reward, next_state)
state = next_state
return modelUnderstanding the variety of training algorithms and their specific mechanisms is crucial for developing effective AI models suited to different tasks and data types. Each type of algorithm offers unique advantages and is suitable for particular kinds of data and outcomes. By selecting and properly tuning these algorithms, data scientists can optimize the performance of their AI models, ensuring accurate and reliable results.
Effective evaluation and optimization are critical for ensuring that AI models perform accurately and reliably in real-world applications. This process involves various metrics and techniques to assess and enhance model performance.
Different metrics are used based on the type of model and the specific problem being addressed.
Pseudocode for calculating accuracy in classification:
def calculate_accuracy(y_true, y_pred):
correct_predictions = np.sum(y_true == y_pred)
accuracy = correct_predictions / len(y_true)
return accuracyCross validation involves splitting the dataset into multiple parts to ensure the model's robustness and prevent overfitting. Common techniques include k-fold cross-validation and leave-one-out cross-validation.
Pseudocode for k-fold cross-validation:
def k_fold_cross_validation(model, data, labels, k):
fold_size = len(data) // k
accuracies = []
for i in range(k):
val_start = i * fold_size
val_end = val_start + fold_size
X_train = np.concatenate([data[:val_start], data[val_end:]])
y_train = np.concatenate([labels[:val_start], labels[val_end:]])
X_val = data[val_start:val_end]
y_val = labels[val_start:val_end]
model.train(X_train, y_train)
predictions = model.predict(X_val)
accuracy = calculate_accuracy(y_val, predictions)
accuracies.append(accuracy)
return np.mean(accuracies), np.std(accuracies)Hyperparameter tuning involves adjusting the settings of an algorithm to improve its performance. This process is crucial for optimizing model performance and achieving the best possible results.
Pseudocode for grid search:
from sklearn.model_selection import GridSearchCV
def grid_search(model, param_grid, X_train, y_train):
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
return grid_search.best_params_, grid_search.best_score_Regularization techniques are used to prevent overfitting by adding a penalty to the model for having too many or too complex parameters. These methods help improve the model's generalization to unseen data by controlling its complexity.
Pseudocode for L2 regularization:
def l2_regularization(weights, lambda_):
return lambda_ * np.sum(weights ** 2)
def train_with_l2(X, y, weights, lr, epochs, lambda_):
for epoch in range(epochs):
predictions = np.dot(X, weights)
errors = predictions - y
gradient = np.dot(X.T, errors) / len(y) + l2_regularization(weights, lambda_)
weights -= lr * gradient
return weightsEffective evaluation and optimization are crucial for ensuring AI models perform accurately and reliably. This process involves assessing various metrics and refining the model to enhance its performance.
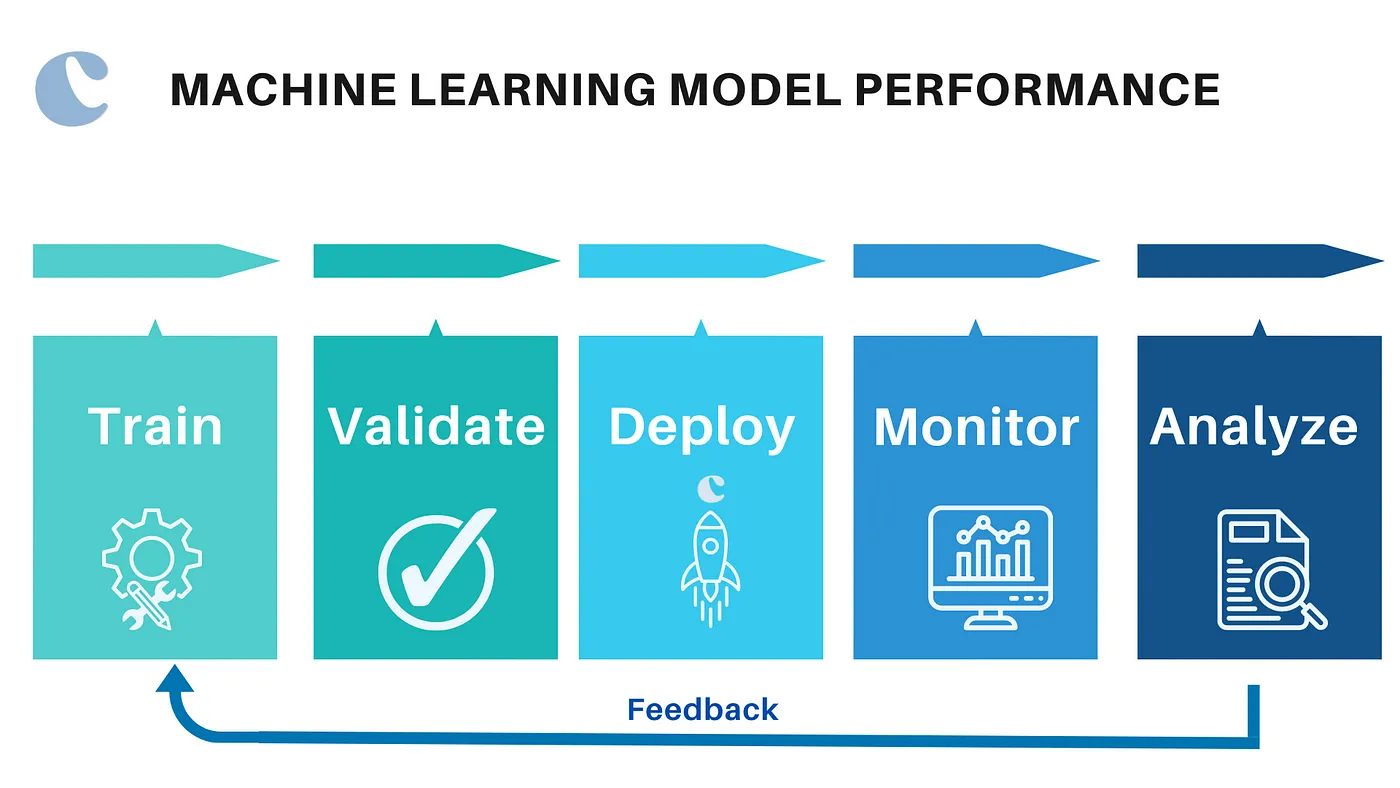
Deploying an AI model involves making it available for use in a production environment. Continuous monitoring ensures the model remains effective over time.
Pseudocode for deploying a model as a REST API using Flask:
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load('model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
prediction = model.predict(data['input'])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)Continuous monitoring of the model's performance in production is essential to detect issues such as model drift, where the statistical properties of the input data change over time.
Pseudocode for logging predictions and monitoring performance:
import logging
logging.basicConfig(filename='model_performance.log', level=logging.INFO)
def log_prediction(input_data, prediction):
logging.info(f"Input: {input_data}, Prediction: {prediction}")
def monitor_performance(predictions, true_labels):
accuracy = calculate_accuracy(true_labels, predictions)
logging.info(f"Model Accuracy: {accuracy}")
if accuracy < threshold:
send_alert(f"Model accuracy dropped to {accuracy}")
def send_alert(message):
# Implementation to send an alert (e.g., email, SMS, etc.)
passOptimizing AI models involves careful attention to data handling, model architecture, training algorithms, evaluation metrics, and continuous monitoring. By leveraging these strategies, data scientists can develop robust, efficient, and effective AI models that deliver high performance in real-world applications. Understanding and applying these principles ensures that AI models perform well in controlled environments and maintain their reliability and accuracy when deployed in production settings.
Stay updated with our latest insights.




























Empower your AI journey with our expert consultants, tailored strategies, and innovative solutions.
