Solution Team
Jul 1, 2024
Category: LLM

The development lifecycle of large language models (LLMs) encompasses a variety of intricate components, including data ingestion, data preparation, prompting techniques, model fine-tuning, deployment, and monitoring. Efficient LLMOps practices are crucial for synchronizing these processes, facilitating smooth transitions between stages. The combined efforts of data scientists, DevOps engineers, and IT professionals are vital for the successful deployment and ongoing enhancement of LLMs.
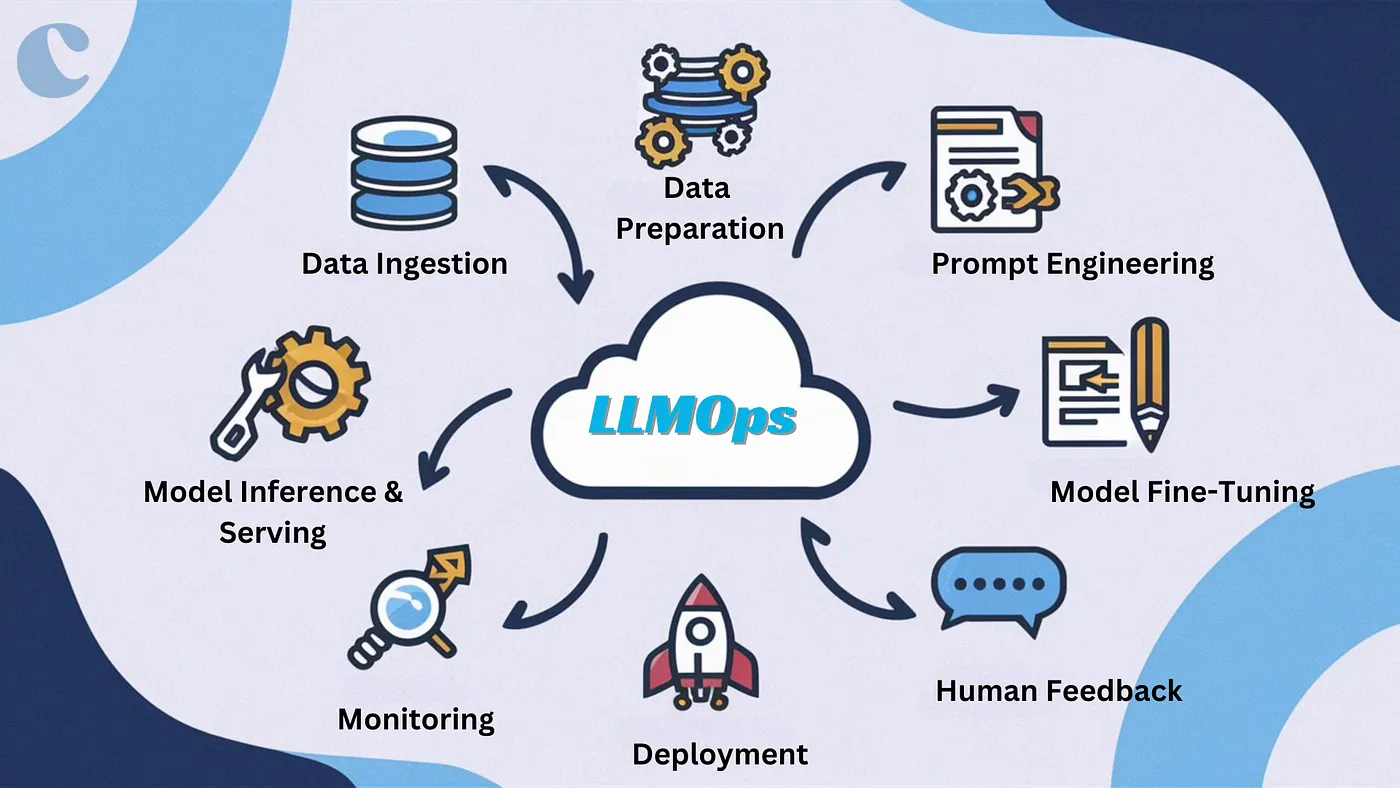
While LLMOps share many principles with MLOps, several unique challenges necessitate tailored approaches:
Training and fine-tuning large language models (LLMs) require significant computational power over vast datasets. Specialized hardware, such as GPUs, is vital for carrying out these tasks efficiently. Having access to these resources is imperative for both the training and deployment of LLMs. Moreover, due to the high cost of inference, it is necessary to employ techniques like model compression and distillation for effective resource management.
LLMs often start from a foundation model and are fine-tuned with domain-specific data. This approach allows for achieving state-of-the-art performance using less data and fewer computing resources compared to training models from scratch.
Reinforcement learning from human feedback (RLHF) plays a significant role in improving LLMs. Since LLM tasks are often open-ended, integrating feedback from end-users is critical for evaluating performance and guiding future fine-tuning.
Hyperparameter tuning in LLMs focuses not only on improving accuracy but also on reducing the cost and computational requirements of training and inference. Optimizing parameters like batch sizes and learning rates can significantly impact the efficiency of the process.
Evaluating LLMs involves different metrics compared to traditional ML models. Metrics like BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are used to assess the performance of LLMs in generating human-like text.
Crafting effective prompts is crucial for obtaining accurate and reliable responses from LLMs. Prompt engineering helps mitigate issues such as model hallucination and prompt hacking, ensuring secure and precise outputs.
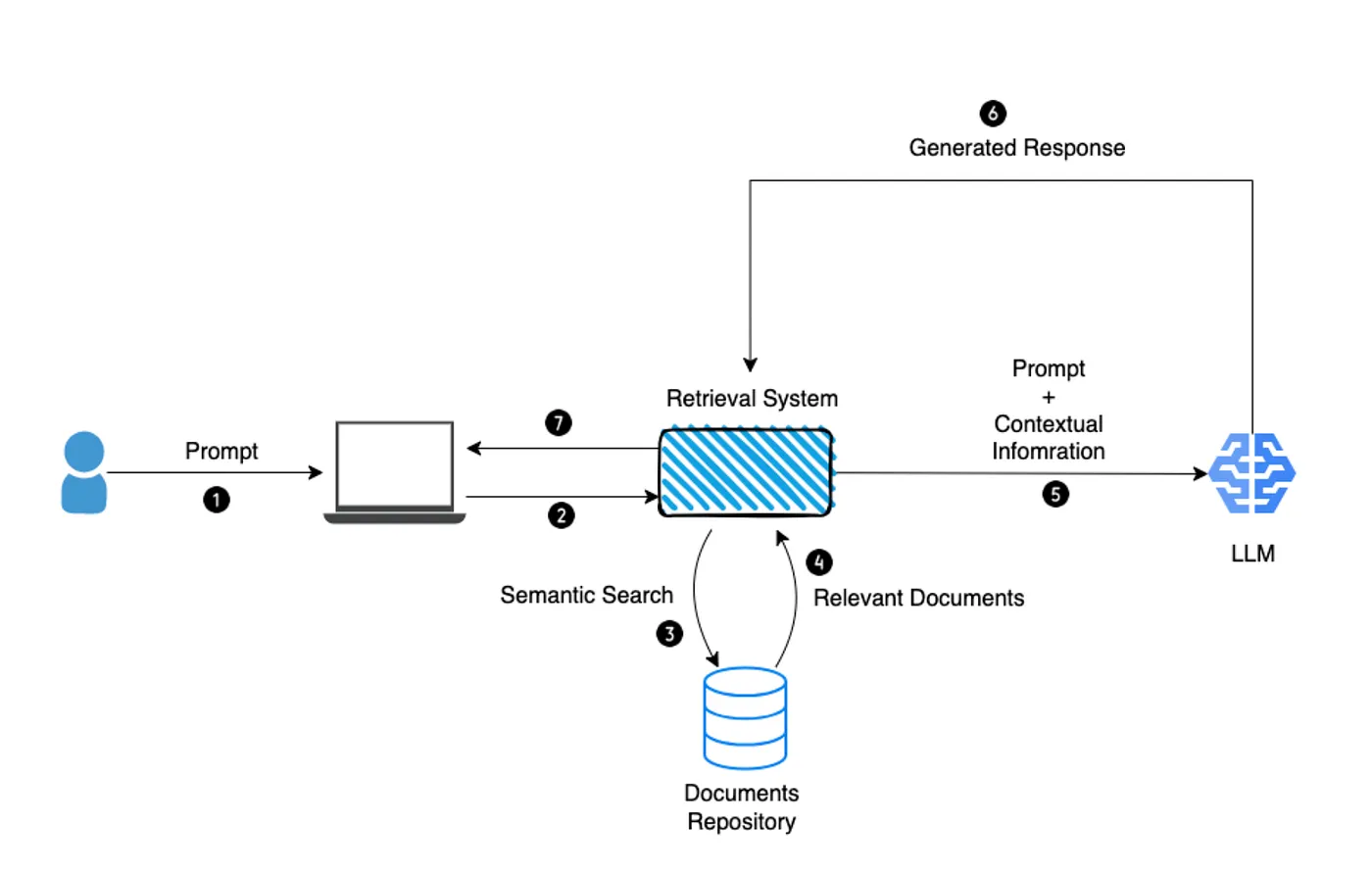
LLM pipelines, built using tools like LangChain or LlamaIndex, enable complex tasks by stringing together multiple LLM calls and integrating external systems. These pipelines are essential for applications like knowledge-based Q&A or document-based queries.
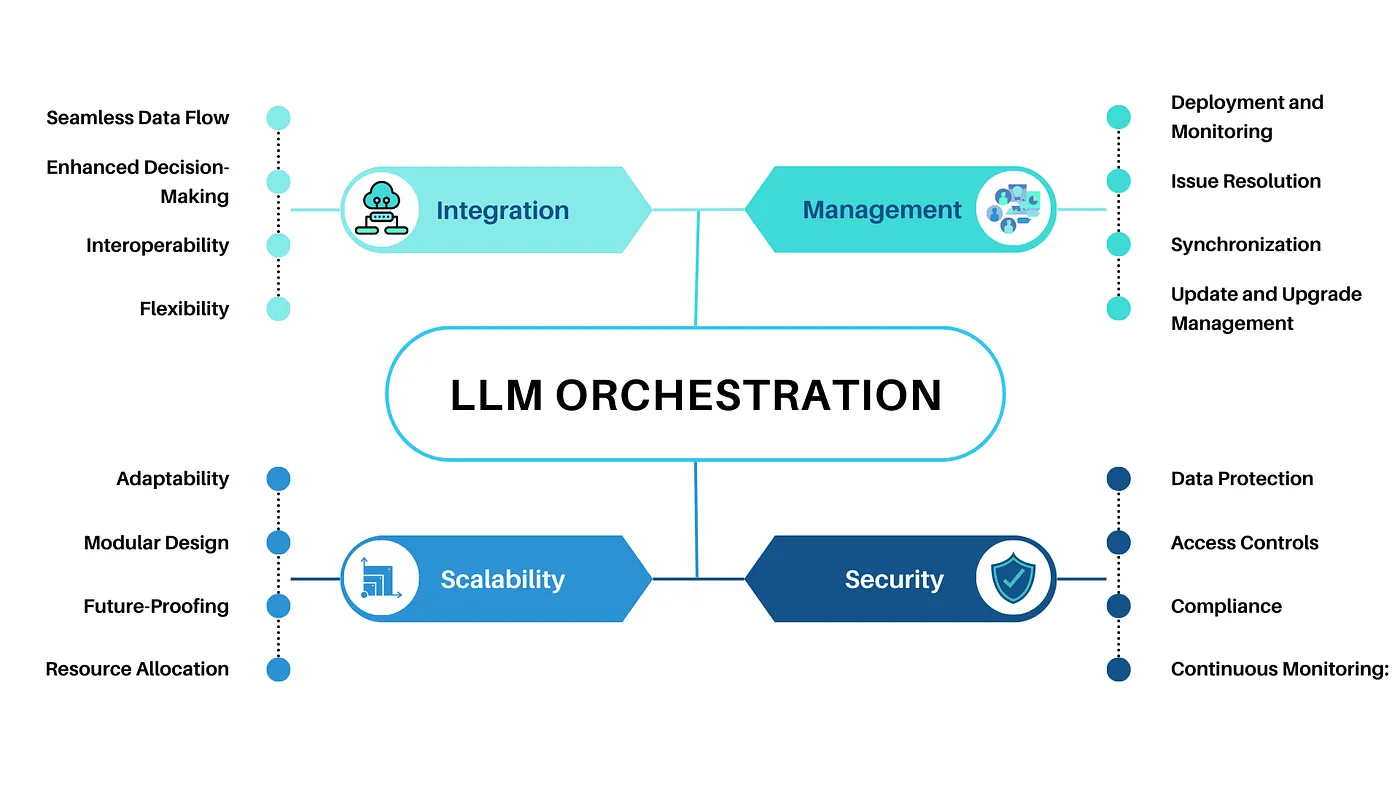
The scope of LLMOps can be broad or narrow, depending on project requirements. Key components typically include:
EDA involves analyzing and preparing data for the ML lifecycle and creating reproducible and shareable datasets and visualizations.
This involves transforming and aggregating data, making it accessible to data teams, and developing prompts for reliable LLM queries.
LLMs Fine-tuning using libraries like Hugging Face Transformers, DeepSpeed, PyTorch, TensorFlow, and JAX to enhance model performance.
Tracking model lineage, and versions, and managing artefacts through their lifecycle. Platforms like MLflow facilitate collaboration and governance.
Managing model refresh frequencies, inference request times, and production specifics using CI/CD tools. Enabling REST API model endpoints with GPU acceleration.
Creating monitoring pipelines with alerts for model drift and malicious behaviour, integrating human feedback for continuous improvement.
Define the goals and expected outcomes of implementing LLMOps, identifying key performance indicators (KPIs) and success metrics.
Encourage collaboration among data scientists, developers, and IT professionals using shared tools and platforms.
Implement automation for repetitive tasks such as data preprocessing, model training, and deployment using CI/CD tools.
Set up robust monitoring systems to track model performance in real-time and implement alerting mechanisms to quickly address any issues.
Regularly audit models to ensure they comply with regulatory requirements and ethical standards, using tools that provide transparency and explainability.
Provide ongoing training for teams to stay updated with the latest LLMOps practices and tools and invest in the necessary infrastructure to support these initiatives.
Continuously refine and improve models based on feedback and new data, implementing a feedback loop to capture insights from production.
LLMOps represents a critical evolution in the operational management of large language models, addressing the unique challenges and complexities of deploying and maintaining these advanced models in production environments. By adopting best practices from both MLOps and DevOps, LLMOps ensures that enterprises can effectively manage the lifecycle of LLMs, from data preparation and model fine-tuning to deployment and continuous monitoring. As AI continues to advance and impact various industries, the adoption of LLMOps will be crucial for organizations looking to leverage the full potential of large language models. With the right strategies and tools, LLMOps can transform the way LLMs are developed, deployed, and managed, leading to more efficient, scalable, and reliable AI-driven solutions. By fostering a collaborative culture, automating processes, and ensuring compliance, LLMOps enables organizations to navigate the complexities of LLM deployment with confidence. As a result, businesses can achieve faster time-to-market, improved model performance, and greater operational efficiency, ultimately driving innovation and success in the rapidly evolving field of artificial intelligence.
Stay updated with our latest insights.




























Empower your AI journey with our expert consultants, tailored strategies, and innovative solutions.
